 |
4000156919 |
|
4000156919 |
来源:巨灵鸟软件 作者:进销存软件 发布:2018/3/3 浏览次数:5145
语音识别,通常称为自动语音识别,英文是Automatic Speech Recognition,缩写为 ASR,主要是将人类语音中的词汇内容转换为计算机可读的输入,一般都是可以理解的文本内容,也有可能是二进制编码或者字符序列。但是,我们一般理解的语音识别其实都是狭义的语音转文字的过程,简称语音转文本识别( Speech To Text, STT )更合适,这样就能与语音合成(Text To Speech, TTS )对应起来。
语音识别是一项融合多学科知识的前沿技术,覆盖了数学与统计学、声学与语言学、计算机与人工智能等基础学科和前沿学科,是人机自然交互技术中的关键环节。但是,语音识别自诞生以来的半个多世纪,一直没有在实际应用过程得到普遍认可,一方面这与语音识别的技术缺陷有关,其识别精度和速度都达不到实际应用的要求;另一方面,与业界对语音识别的期望过高有关,实际上语音识别与键盘、鼠标或触摸屏等应是融合关系,而非替代关系。
深度学习技术自 2009 年兴起之后,已经取得了长足进步。语音识别的精度和速度取决于实际应用环境,但在安静环境、标准口音、常见词汇场景下的语音识别率已经超过 95%,意味着具备了与人类相仿的语言识别能力,而这也是语音识别技术当前发展比较火热的原因。
随着技术的发展,现在口音、方言、噪声等场景下的语音识别也达到了可用状态,特别是远场语音识别已经随着智能音箱的兴起成为全球消费电子领域应用最为成功的技术之一。由于语音交互提供了更自然、更便利、更高效的沟通形式,语音必定将成为未来最主要的人机互动接口之一。
当然,当前技术还存在很多不足,如对于强噪声、超远场、强干扰、多语种、大词汇等场景下的语音识别还需要很大的提升;另外,多人语音识别和离线语音识别也是当前需要重点解决的问题。虽然语音识别还无法做到无限制领域、无限制人群的应用,但是至少从应用实践中我们看到了一些希望。
本篇文章将从技术和产业两个角度来回顾一下语音识别发展的历程和现状,并分析一些未来趋势,希望能帮助更多年轻技术人员了解语音行业,并能产生兴趣投身于这个行业。
语音识别的技术历程
现代语音识别可以追溯到 1952 年,Davis 等人研制了世界上第一个能识别 10 个英文数字发音的实验系统,从此正式开启了语音识别的进程。语音识别发展到今天已经有 70 多年,但从技术方向上可以大体分为三个阶段。
下图是从 1993 年到 2017 年在 Switchboard 上语音识别率的进展情况,从图中也可以看出 1993 年到 2009 年,语音识别一直处于 GMM-HMM 时代,语音识别率提升缓慢,尤其是 2000 年到 2009 年语音识别率基本处于停滞状态;2009 年随着深度学习技术,特别是 DNN 的兴起,语音识别框架变为 DNN-HMM,语音识别进入了 DNN 时代,语音识别精准率得到了显著提升;2015 年以后,由于“端到端”技术兴起,语音识别进入了百花齐放时代,语音界都在训练更深、更复杂的网络,同时利用端到端技术进一步大幅提升了语音识别的性能,直到 2017 年微软在 Swichboard 上达到词错误率 5.1%,从而让语音识别的准确性首次超越了人类,当然这是在一定限定条件下的实验结果,还不具有普遍代表性。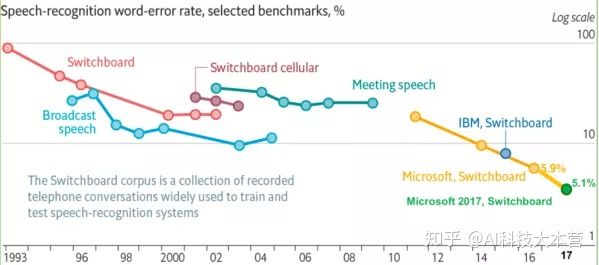
GMM-HMM时代
70 年代,语音识别主要集中在小词汇量、孤立词识别方面,使用的方法也主要是简单的模板匹配方法,即首先提取语音信号的特征构建参数模板,然后将测试语音与参考模板参数进行一一比较和匹配,取距离最近的样本所对应的词标注为该语音信号的发音。该方法对解决孤立词识别是有效的,但对于大词汇量、非特定人连续语音识别就无能为力。因此,进入 80 年代后,研究思路发生了重大变化,从传统的基于模板匹配的技术思路开始转向基于统计模型(HMM)的技术思路。
HMM 的理论基础在 1970 年前后就已经由 Baum 等人建立起来,随后由 CMU 的 Baker 和 IBM 的 Jelinek 等人将其应用到语音识别当中。HMM 模型假定一个音素含有 3 到 5 个状态,同一状态的发音相对稳定,不同状态间是可以按照一定概率进行跳转;某一状态的特征分布可以用概率模型来描述,使用最广泛的模型是 GMM。因此 GMM-HMM 框架中,HMM 描述的是语音的短时平稳的动态性,GMM 用来描述 HMM 每一状态内部的发音特征。
基于 GMM-HMM 框架,研究者提出各种改进方法,如结合上下文信息的动态贝叶斯方法、区分性训练方法、自适应训练方法、HMM/NN 混合模型方法等。这些方法都对语音识别研究产生了深远影响,并为下一代语音识别技术的产生做好了准备。自上世纪 90 年代语音识别声学模型的区分性训练准则和模型自适应方法被提出以后,在很长一段内语音识别的发展比较缓慢,语音识别错误率那条线一直没有明显下降。
DNN-HMM时代
2006年,Hinton 提出深度置信网络(DBN),促使了深度神经网络(DNN)研究的复苏。2009 年,Hinton 将 DNN 应用于语音的声学建模,在 TIMIT 上获得了当时最好的结果。2011 年底,微软研究院的俞栋、邓力又把 DNN 技术应用在了大词汇量连续语音识别任务上,大大降低了语音识别错误率。从此语音识别进入 DNN-HMM 时代。
DNN-HMM主要是用 DNN 模型代替原来的 GMM 模型,对每一个状态进行建模,DNN 带来的好处是不再需要对语音数据分布进行假设,将相邻的语音帧拼接又包含了语音的时序结构信息,使得对于状态的分类概率有了明显提升,同时DNN还具有强大环境学习能力,可以提升对噪声和口音的鲁棒性。
简单来说,DNN 就是给出输入的一串特征所对应的状态概率。由于语音信号是连续的,不仅各个音素、音节以及词之间没有明显的边界,各个发音单位还会受到上下文的影响。虽然拼帧可以增加上下文信息,但对于语音来说还是不够。而递归神经网络(RNN)的出现可以记住更多历史信息,更有利于对语音信号的上下文信息进行建模。
由于简单的 RNN 存在梯度爆炸和梯度消散问题,难以训练,无法直接应用于语音信号建模上,因此学者进一步探索,开发出了很多适合语音建模的 RNN 结构,其中最有名的就是 LSTM 。LSTM 通过输入门、输出门和遗忘门可以更好的控制信息的流动和传递,具有长短时记忆能力。虽然 LSTM 的计算复杂度会比 DNN 增加,但其整体性能比 DNN 有相对 20% 左右稳定提升。
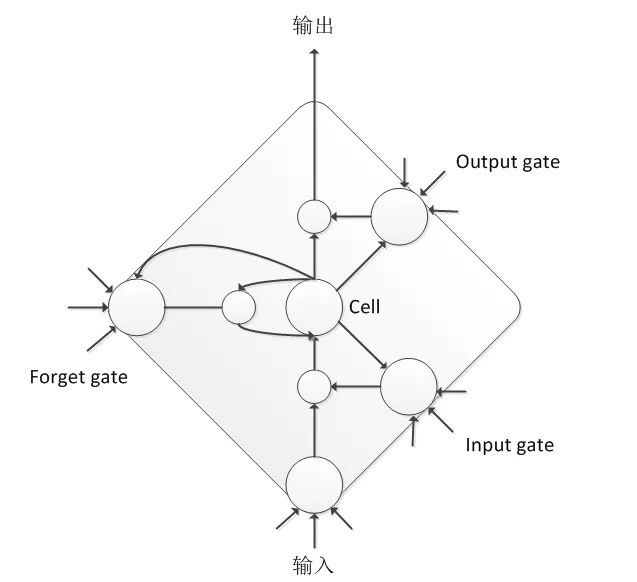
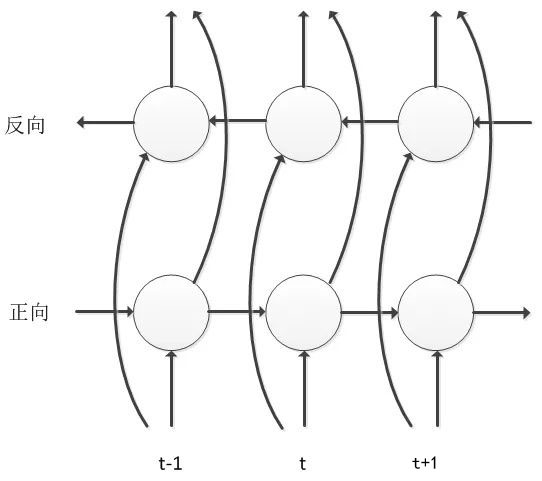
BLSTM 是在 LSTM 基础上做的进一步改进,不仅考虑语音信号的历史信息对当前帧的影响,还要考虑未来信息对当前帧的影响,因此其网络中沿时间轴存在正向和反向两个信息传递过程,这样该模型可以更充分考虑上下文对于当前语音帧的影响,能够极大提高语音状态分类的准确率。BLSTM 考虑未来信息的代价是需要进行句子级更新,模型训练的收敛速度比较慢,同时也会带来解码的延迟,对于这些问题,业届都进行了工程优化与改进,即使现在仍然有很多大公司使用的都是该模型结构。
图像识别中主流的模型就是 CNN,而语音信号的时频图也可以看作是一幅图像,因此 CNN 也被引入到语音识别中。要想提高语音识别率,就需要克服语音信号所面临的多样性,包括说话人自身、说话人所处的环境、采集设备等,这些多样性都可以等价为各种滤波器与语音信号的卷积。而 CNN 相当于设计了一系列具有局部关注特性的滤波器,并通过训练学习得到滤波器的参数,从而从多样性的语音信号中抽取出不变的部分,CNN 本质上也可以看作是从语音信号中不断抽取特征的一个过程。CNN 相比于传统的 DNN 模型,在相同性能情况下,前者的参数量更少。
综上所述,对于建模能力来说,DNN 适合特征映射到独立空间,LSTM 具有长短时记忆能力,CNN 擅长减少语音信号的多样性,因此一个好的语音识别系统是这些网络的组合。
来源:巨灵鸟 欢迎分享本文
上一个文章:技术一旦被用来作恶,究竟会有多可怕(一)
下一个文章:语音识别技术简史(二)